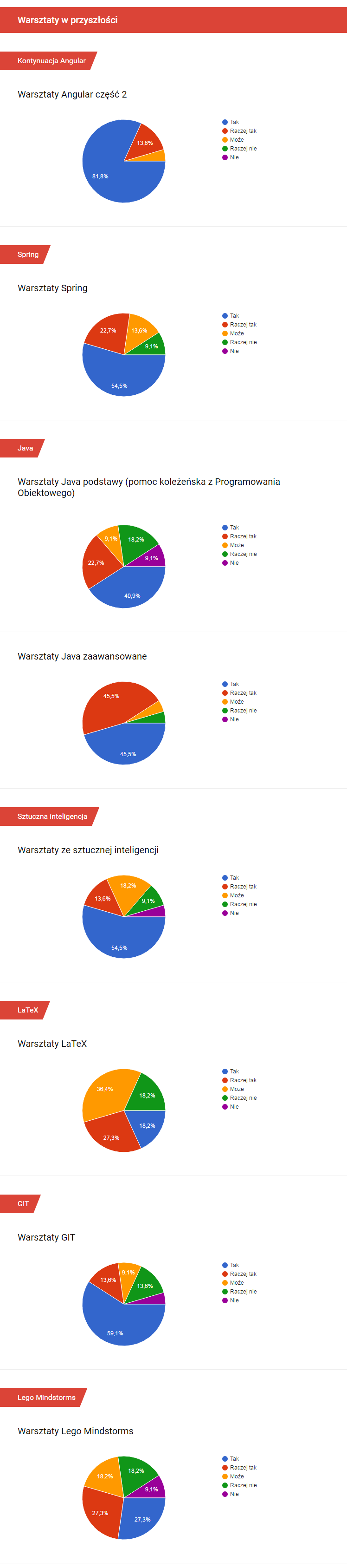
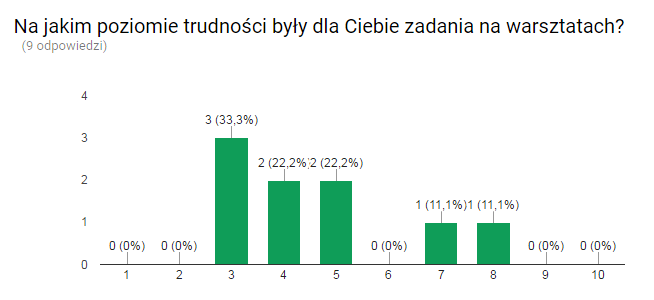
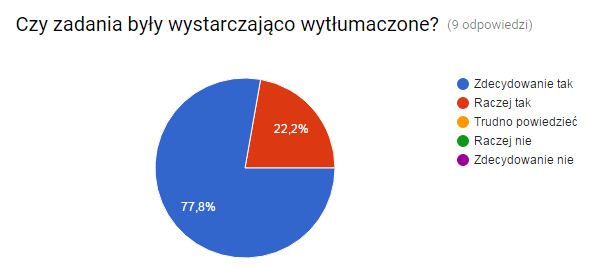
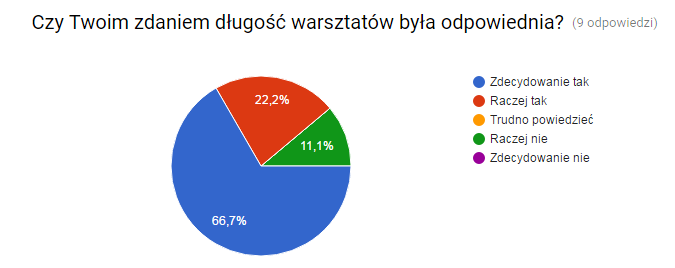
Okres wiosenny obfituje w wiele wydarzeń IT. Jednym z nich są Warszawskie Dni Informatyki, które stały się dużym i ważnym punktem w tym obszarze. W tym roku uczestniczyłem w konferencji w dwojaki sposób: jako słuchacz i jako wystawca na firmowym stoisku. Poniżej opowieść o dwóch dniach WDI bardziej już jako programisty Javy niż studenta.
Dziewiąta edycja WDI
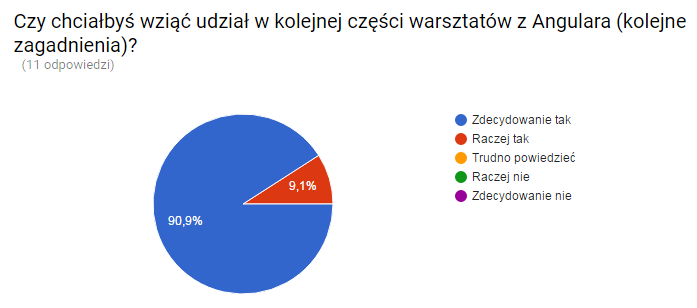
27-28 marca 2018 odbyła się kolejna edycja Warszawskich Dni Informatyki. Główną częścią była oczywiście konferencja, czyli wiele różnych prezentacji, w tym nowości, ale także inspiracji. Świetnym uzupełnieniem do tego jest Giełda Pracy IT. Wielu studentów, którym zależy na poszerzaniu wiedzy, zaczynało tutaj swoją karierę w komercyjnej pracy w IT.
Wydarzenie to cenię szczególnie i darzę pewnym sentymentem. Biorę w nim udział od sześciu lat, czyli od początku studiów. Zdawałem relację z poprzedniej edycji (relacja WDI 2017), jak i wcześniejszych (relacja WDI 2016 i historia). Większość znajomych, którym polecam to wydarzenie, chętnie na nie przybywają. Gdy byłem jeszcze studentem, przychylnie patrzyła na wyjazd uczelnia, a teraz gdy już pracuję, przychylna jest także firma. Cieszę się, że są ludzie, którzy widzą wartość takich wydarzeń i sens uczestniczenia w nich.

Koszulki z kolejnych edycji WDI. Od lewej: 2018, 2017, 2016, 2015, 2014, 2013.
Co roku uczestnikom rozdawane są giftbagi, w których znajdują się koszulki. Kolekcjonuję je od pierwszej edycji, na której byłem. Przy okazji, są bardzo wygodne 😉 Ktoś wie jak wyglądały w edycjach 2012, 2011, 2010 (o ile w ogóle były)?
Organizacja
Ogólne ramy wydarzenia nie zmieniły się od kilku lat, widać sprawdzają się. Było jednak kilka różnic, niektóre na plus, a niektóre na minus.
Strona internetowa
Podobna jak w poprzednich latach. Owszem, ładna, interaktywna, zgodna z modą one page scroll, ale też bardzo ciężka. Strona konferencji powinna być przede wszystkim funkcjonalna i lekka. Ta potrafiła się ładować zdecydowanie za długo – szczególnie podczas największego obciążenia i na urządzeniach mobilnych, czyli w tych przypadkach kiedy była najbardziej potrzebna.
Dodajmy do tego agendę, która przy dużym obciążeniu przestawała działać na urządzeniach mobilnych (nagłówki się rozwijały, ale nie dało się zobaczyć godzin z tytułami wystąpień). Sprawy nie ułatwiał słaby dostęp do internetu – w niektórych salach zasięg sieci komórkowej był praktycznie niemożliwy do złapania, a udostępnionego publicznie WiFi nie było (był tylko dla wystawców; ale to akurat rozumiem, bo pewnie problematyczne było załatwienie infrastruktury na kilka tysięcy osób). Niektórzy próbowali nawet robić własne wersje agendy.
Takie sytuacje ratują wydrukowane agendy, które na miejscu może każdy wziąć. Przy tylu ulotkach, plakatach i książeczkach reklamowych dodatkowa kartka z agendą (czyli tym co najważniejsze!) nie powinno być problemem. Co roku tak było. Niestety w tym roku w rozdawanych książeczkach z opisem firm zabrakło agendy 🙁 Nie wiem co było przyczyną, ale mogę się domyślać, że to przez zmiany w agendzie, które miały pojawić się już po przygotowaniu materiałów.
Wystarczyło na stronie udostępnić prostą wersję tekstową agendy i/lub przesłać ją na emaila – rozwiązałoby to powyższe problemy.
Można było jeszcze usłyszeń zarzut do strony, że przy rejestracji po kliknięciu checkboxa zmiany są od razu zapisywane (bardziej intuicyjny były przycisk do zatwierdzenia zmian). Powodowało to, że niektórzy nieświadomie odznaczając checkboxa wypisywali się z rezerwacji, a przy ponownej próbie zapisania miejsc już nie było. Na pewno wartościową funkcją była informacja o wyczerpujących się miejscach na poszczególne wykłady.
Rejestracja na miejscu
Wreszcie nie było kolejek do rejestracji podczas wydarzenia! Kody QR i odpowiednia liczba osób z aplikacjami na smartfonach do skanowania spełniła swoje zadanie wyśmienicie. W poprzednich latach też były kody QR, ale proces był dużo dłuższy, a wężyk ciągnął się nawet pomiędzy stoiskami firm. Teraz system działał poprawnie, a po udanym zarejestrowaniu przychodził nawet SMS z potwierdzeniem.
Kolejki były za to do giftbagów i pizzy. Ale nie jest to krytyczna część wydarzenia, a te pierwsze można było odebrać w innych godzinach bez kolejek (szkoda tylko, że nie było nigdzie wywieszonego spisu tych godzin).
W tym roku można było także wykupić udział VIP. Czyżby to była próba zwiększenia budżetu wydarzenia lub uniezależnienia się od sponsorów? Udział taki zapewniał catering i miejsce na sali w wydzielonej części. To drugie powodowało marnotrawienie części miejsc w salach (przeważnie sekcja VIP nie była wypełniona).
Jak to na wydarzeniach, ogólnie było dużo ludzi. Tutaj skala była taka, że miejscami robiło się tłoczno. Cieszy to, bo co roku przybywa uczestników. Jednak może by warto pomyśleć nad jakimś większym miejscem i chociaż jedną dużą salą wykładową, która pomieści więcej uczestników (szczególnie jeśli chodzi o otwarcie i najbardziej oblegane wykłady na głównych ścieżkach).
Stoisko firmowe
W tym roku uczestniczyłem w konferencji w dwojaki sposób: jako uczestnik i jako wystawca. W firmie, w której pracuję wyraziłem chęć, że w tym roku, jak co roku, chciałbym uczestniczyć w konferencji, a przy tym mógłbym również reprezentować firmę na stoisku Giełdy Pracy IT.
Co ciekawe, firma w której pracuję wystawiała się również w poprzednim roku, gdzie ją pierwszy raz zauważyłem. Dlatego wydaje mi się, że skuteczność rekrutacji tutaj jest stosunkowo wysoka (szczególnie juniorów). Pamiętałem również z poprzednich lat, że bardzo wartościowe jest jak można zamienić słowo z osobą techniczną (np. programistą). Chciałem tym razem zobaczyć jak to wygląda z drugiej strony.
Prowadziliśmy rekrutację na trzy stanowiska:
- Młodszy programista Java
- Młodszy programista .Net
- Tester
Czekamy na Was na Warszawskich Dniach Informatyki ☺ #WDI2018 #WDI pic.twitter.com/yxfyOfPVQY
— BMS sp. z o.o. (@BMS_devs) March 27, 2018
Stanie kilka godzin i opowiadanie ciągle tego samego jest dosyć wymagające i męczące. Najciekawsze dla mnie były pytania techniczne, o to jakich technologii używamy, jak wygląda dzień pracy, rozmowa o tym co kandydat powinien umieć itd. Niestety takich szczegółowych pytań było niewiele. W pozostałych przypadkach bardzo pomocne okazały się materiały:
- oferty pracy ze szczegółami (czyli takie FAQ, które każdy może sam przeczytać i wziąć ze sobą, żeby pamiętać),
- broszura o firmie (ogólne informacje o firmie, czym się zajmuje, jak wyglądają sale),
- zagadki!
Większość z tych informacji można znaleźć na stronie: http://bms.com.pl/, jednak podczas wydarzenia warto było je mieć pod ręką.
Zagadki
Punkt ostatni był bardzo fajny, gdyż przerywał monotonię, przyciągał uczestników i pomagał w zorientowaniu się w wiedzy kandydatów.
Przygotowane były zadania z czterech obszarów: Java, .Net, SQL i zagadki logiczne. Za rozwiązanie zagadki można było wygrać kaczkę! Kto nie słyszał o tłumaczeniu kaczce kodu, odsyłam do Wikipedii: metoda gumowej kaczuszki.

„Przeczytaj mi swój kod” ~ firmowa kaczuszka BMS
Zadania zawierały kilka haczyków. Nie mogły być zbyt trudne, ale też nie mogły być zbyt szybkie do rozwiązania. Nie były to też testy rekrutacyjne, bo ciężko traktować tak rozwiązania na kolanie w biegu. Ze względu na haczki był to bardziej test na spostrzegawczość. Ale najcenniejsza nie była odpowiedź kandydata, a tok rozumowania i użyta wiedza podczas tłumaczenia próby rozwiązania zagadek. Dzięki temu był punkt zaczepienia do technicznej rozmowy i pobieżne zorientowanie się w ogólnym poziomie wiedzy kandydata z danego zagadnienia.
Poniżej przedstawiam zadania z Javy, które przygotował kolega z zespołu.
Zadanie 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
abstract class Writer { public static void write() { System.out.println("Writing..."); } } class Student extends Writer { public static void write() { System.out.println("Writing exam"); } } public class Programmer extends Writer { public static void write() { System.out.println("Writing code"); } public static void main(String[] args) { Writer w = new Student(); w.write(); } } |
Zadanie 2.
|
1 2 3 4 5 6 7 8 9 10 |
public class BMSClass { public static void main(String[] args) { StringBuilder s1 = new StringBuilder("BMS"); String s2 = "Love"; s1.append(s2); s1.substring(4); int foundAt = s1.indexOf(s2); System.out.println(foundAt); } } |
Pytanie oczywiście: jaki będzie wynik wykonania programu?
Poniżej zamieszczam rozwiązania wraz z wytłumaczeniem. Ale jeśli znasz podstawy Javy, spróbuj najpierw sam.
Rozwiązanie zadania 1
Program w Javie zaczyna się wykonywać w klasie publicznej public class, w której jest metoda main: public static void main(String[] args). Jest to klasa Programmer z metodą main. Inicjalizowana jest zmienna o nazwie w typu Writer nowym obiektem typu Student. W Javie typem zmiennej może być klasa. Widzimy tutaj właśnie te dwie klasy: Writer i Student.
Dlaczego do zmiennej typu Writer można było przypisać obiekt typu Student? Spójrzmy na te klasy. Klasa Student dziedziczy po klasie Writer. Innymi słowy, klasa Student rozszerza (extends) klasę Writer: Student extends Writer. Dzięki dziedziczeniu możliwy jest polimorfizm (wielopostaciowość). Metody istniejące w klasie rodzica (Writer) mogą zostać nadpisane przez metody klasy dziecka (Student).
Kolejna linia w metodzie main to wywołanie metody write(). Tylko która metoda się wykona i który tekst zostanie wypisany na ekran? Zgodnie z tym co napisałem w poprzednim akapicie, obiekt typu Student powinien nadpisać metodę write() klasy nadrzędnej Write, bo mimo tego, że zmienna (referencja) jest typu Writer, to obiekt w rzeczywistości jest typu Student. Czyli według tego na ekran powinno wypisać się Writing exam.
Tutaj jest jednak haczyk, słówko static. Gdyby ich nie było, to działoby się tak jak napisane wyżej. W zadaniu jest inaczej, bo metody statyczne (oznaczone słówkiem static) nie podlegają polimorfizmowi, nie są nadpisywane (ang. overriding). Zmienna w jest typu Writer, a więc w tym wypadku, przy metodach statycznych nie ma znaczenia typ przypisanego obiektu. Wywołanie w.writer() jest tutaj równoznaczne z Writer.write(). Dlatego wynikiem będzie Writing....
Warto dodać, że o ile nie jest możliwe nadpisywanie metod statycznych (ang. overriding), to możliwe jest ich przesłanianie (ang. redefinition) tzn. w klasach dziedziczących mogą być zdefiniowane metody statyczne o takich samych nazwach jak metody w klasie nadrzędnej. Widać to w tym zadaniu. (Wywołać taką przesłoniętą metodę można za pomocą Student.write() lub zdefiniowania zmiennej typu podrzędnego Student w i wywołania w.write().) Jeśli któraś z tych metod nie byłaby oznaczona jako statyczna (a pozostałe o takich samych nazwa byłyby), to próba skompilowania zostałaby zakończona błędem (z powodu próby nadpisania metody statycznej).
Oznaczenie klasy Writer jako abstrakcyjnej abstract, w tym zadaniu nie miało żadnego wpływu. Podobnie metoda write() w klasie Programmer nie było nigdzie wykorzystana.
Rozwiązanie zadania 2
W tego typu zadaniach warto sobie wypisywać co po kolei będą przyjmować zmienne.
StringBuilder s1 = new StringBuilder("BMS");– Inicjalizacja zmiennejs1utworzonym obiektem typuStringBuilderz parametremBMS. W uproszczeniu, patrząc na zachowanie, jest to przypisanie tekstuBMSdo zmiennejs1czyli coś w styluString s1 = "BMS". Użyty został jednak obiekt klasyStringBuilder, a nieString, aby wykorzystać potem metodęappend()(klasaStringnie udostępnia takiej metody).String s2 = "Love";– Oczywiste przypisanie. W zmiennejs1mamyBMS, w zmiennejs2mamyLove.s1.append(s2);– Wywołanie metodyappendna rzecz obiektu klasyStringBuilderz parametrems2. W uproszczeniu jest to dodanie do zmiennejs1tekstus2. Czyli wynikiem będzieBMSLove. Gdyby to nie był obiekt StringBuilder tylko String, to taki sam wynik miałobys1 += s2.s1.substring(4);– Zazwyczaj używamy tej metody z dwoma parametramisubstring(start, end), która zwraca tekst zaczynając od indeksustart(włącznie), aż do indeksuend(bez tego ostatniego). Metoda z jednym parametremsubstring(start)zwraca tekst zaczynając od indeksustart(włącznie) aż do końca. Czyli odpowiednikiems1.substring(4)jests1.substring(s1.length()). Tekstem jestBMSLove, a więc ta metoda zwróci tekstu zaczynając od znaku pod indeksem4(oczywiście liczymy od zera, więcB=0, M=1, S=2, L=3, o=4) czyliove.int foundAt = s1.indexOf(s2);– MetodaindexOfszuka podanego ciągu znaków jako parametr i jeśli znajdzie to zwraca indeks pierwszego znaku w napotkanym ciągu, a jeśli nie znajdzie, to zwraca-1. Wynik zapisywane jest do zmiennej, a w kolejnej linii zapisywany.
Jeśli s1 jest równe ove, a s2 jest równe Love, to tekst Love nie zostanie znaleziony w tekście ove, więc zostanie zwrócone i wypisane -1.
Czy jednak tak będzie? Tutaj haczyk. Wróćmy do punktu 4. Metoda substring tylko zwraca tekst, a nie przypisuje go jak metoda append. W takim razie przy analizowaniu można tę linię w ogóle pominąć, bo nie wpływa na końcowy wynik (nie modyfikuje tych zmiennych).
Czyli s1 jest równe BMSLove, a s2 jest równe Love, więc tekst Love zostanie znaleziony w tekście BMSLove. Indeks pozycji pierwszego znalezionego znaku to 3 (liczymy od zera B=0, M=1, S=2, L=3) i taka wartość zostanie przypisana do zmiennej, a następnie wypisana.
Jeśli chcielibyśmy, aby metoda substring zmodyfikowała nam zmienną s1, to można by zrobić np. tak: s1 = new StringBuilder(s1.substring(4)), czyli utworzyć nowy obiekt StringBuilder i jako parametr podać zwróconą wartość przez substringa. Nie możemy zrobić po prostu s1 = s1.substring(4), bo zmienna s1 jest typu StringBuilder, a substring zwraca obiekt typu String. Innym rozwiązaniem jest skorzystanie z metody klasy StringBuilder, która modyfikuje wartość zmiennej np. s1.delete(0, 4) czyli usunięcie tekstu od początku (włącznie) do pozycji 4 (bez tej pozycji). Jest to odwrotność wyżej omawianego substringa.
Wykłady
W tym roku wszystkie wykłady zostały podzielone na tematyczne ścieżki. Myślę, że to dobry krok, bo łatwiej znaleźć to co cię interesuje, a także jest mniejsze ryzyko, że w tym samym czasie będą trwały wykłady, które chciałbyś wysłuchać. Ważne to zwłaszcza przy tym, że wykłady nie są nagrywane (chociaż można znaleźć nagrania niektórych, o tym niżej) ani nie ma streamu online (o ile mnie pamięć nie myli to kiedyś część była streamowana).
Widać nasilający się trend z poprzednich lat, że ścieżki przygotowują zewnętrzne organizacje/grupy osób. Były to m.in. meet.js, Warsaw Java User Group, Women in Technology, Zaufana Trzecia Strona, Google Developers Group i SysOps/DevOps Polska. Z jednej strony odciąża to organizatorów WDI, a specjalistom z danej dziedziny, którzy często organizują spotkania w swoim gronie łatwiej przygotować merytoryczną ścieżkę z danego obszaru. Z drugiej zaś strony zmniejsza to rangę samego WDI (idzie to w kierunku kilku równoległych meetupów, które normalnie odbywają się w ciągu całego roku) oraz całe wydarzenie trochę traci na interdyscyplinarności (wcześniej różne tematy się przeplatały, można było poznać różne obszary, teraz jest to bardziej hermetyczne).
Niektóre grupy/osoby idą też na łatwiznę i zaprezentowały wystąpienia już pokazywane wcześniej. Były nawet takie, których nagrania są już np. na Youtube. Czy jest sens kolejny raz mówić to samo? Zwłaszcza jak każdy może obejrzeć to w domu? Rozumiem, że jak ktoś przygotował dobrą prezentację to chce pokazać ją innym (na WDI była większa szansa, że więcej osób ją zobaczy niż jakby tylko leżało nagranie na Youtube), ale może jednak warto byłoby spróbować przygotować coś nowego.
Mnie jako programistę Java interesowała głównie ścieżka Java development by Warsaw Java User Group. Liczyłem też na zdobycie ogólnej wiedzy z IT, szczególnie odnośnie trendów i nowości. Hobbystycznie chciałem też posłuchać o uczeniu maszynowym (Machine Learning).
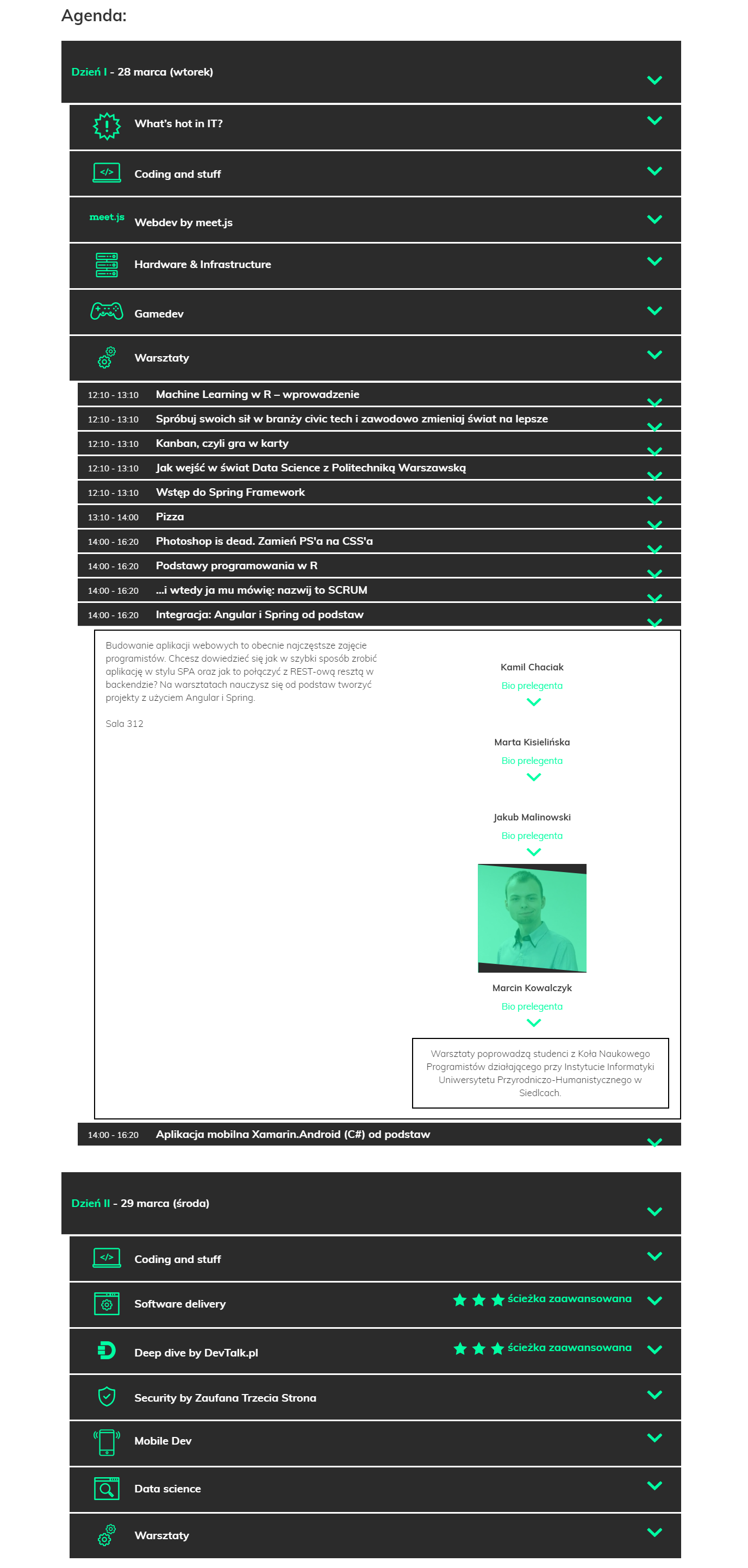
Agenda ze strony warszawskiedniinformatyki.pl (częściowa kopia na WebCite):
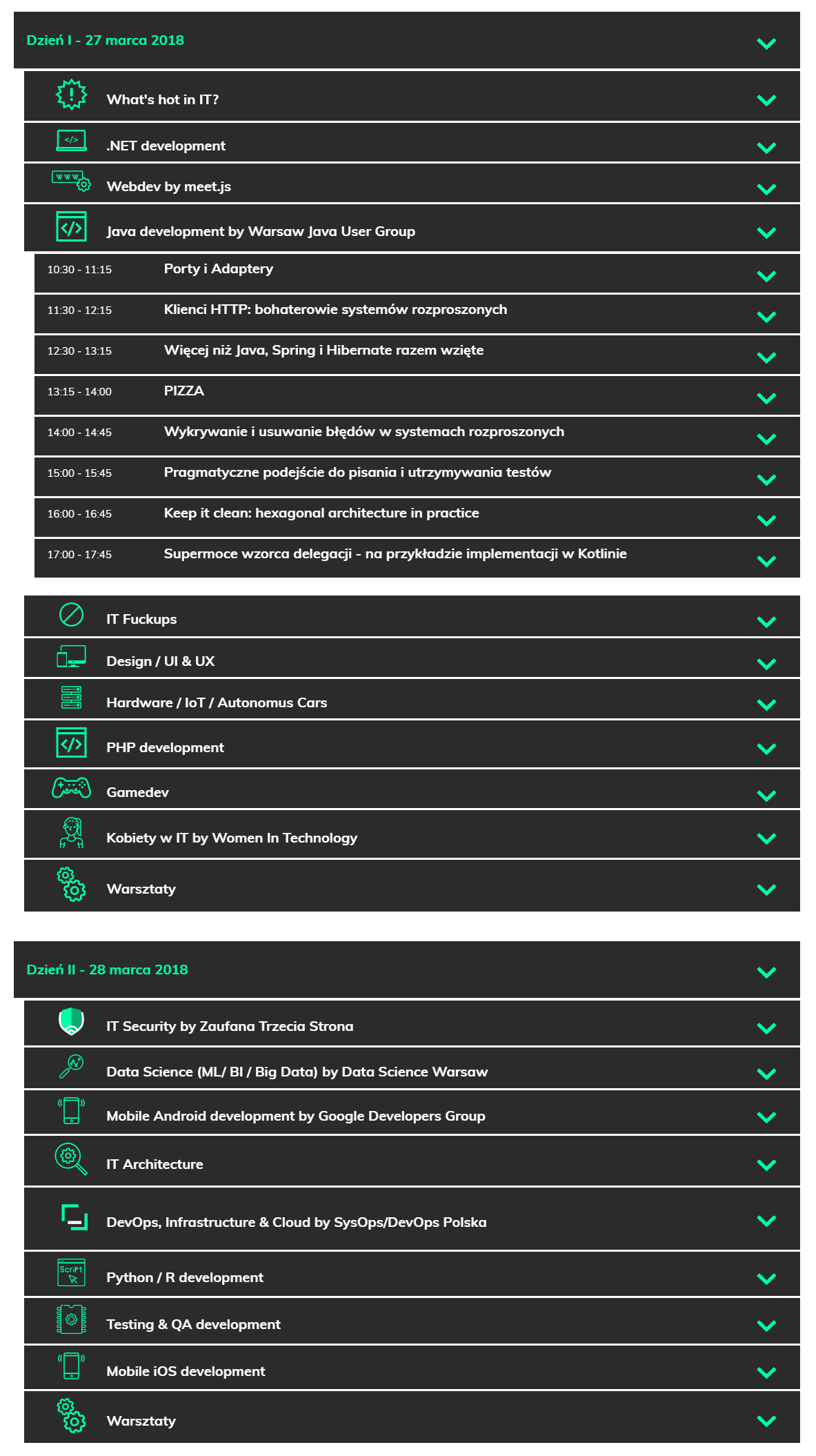
- Otwarcie konferencji wyglądało jak w poprzednich latach, chociaż trochę dziwne było, że w innych salach wykłady zaczęły się już równolegle. Być może to celowy krok, żeby rozłożyć dużą liczbę osób na kilka sal już od początku.
- Zawsze ceniłem wykłady sponsorów po otwarciu. Firmy często dobrze się przygotowywały chcąc pokazać się z jak najlepszej strony (w końcu zainwestowały w to wydarzenie dużo środków) , a nie tylko pokazać materiał reklamowy. W poprzednich latach z Asseco występował Adam Góral (prezes) opowiadając o powstawaniu firmy z pierwszej ręki, Artur Wiza (człowiek od marketingu, ale mówiący rzeczowo) lub przygotowywane prezentacje przekazywały jakieś ciekawostki. W tym roku trochę się zawiodłem. Prezentacja pt. Duże transformacje IT – Praktyczne wnioski na podstawie największego w projektu IT polskiego Telco ostatnich 10 lat nie porywała. Domyślam się, że w założeniu miała pokazać jakieś techniczne aspekty i jakie to świetne projekty robi firma. Niestety prezentacja to trochę obrazków, kilka screenów z nieomówioną architekturą i trochę marketingowej papki. Niestety sam sposób prezentacji też była słaby. Rozumiem stres i być może małe doświadczenie prelegentów w wystąpieniach publicznych. Ale czytanie z kartki podczas prezentacji jest niedopuszczalne, nie wspominając o szukaniu informacji w pliku kartek… Być może prezentacja to był rzut na głęboką wodę, ale nie rozumiem tego posunięcia (w tak dużej firmie z pewnością znalazłby się ktoś bardziej doświadczonych w takich prezentacjach; warto najpierw występować na mniejszych wydarzeniach, a dopiero potem na takich o większym znaczeniu). Został trochę zmarnowany potencjał.
- Kolejna prezentacja sponsora to Accenture Technology Vision 2018. Nie byłem na niej, ale domyślam się, że tak samo jak w poprzednich latach była to prezentacja raportu o trendach w branży IT. Prelegentem był Jacek Borek, czyli również ta sama osoba co w tamtym roku. Z tegorocznym raportem można zapoznać się w formacie PDF po angielsku (Accenture-TechVision-2018-Tech-Trends-Report.pdf) lub w formie skróconej w języku polskim na stronie (Era inteligentnych przedsiębiorstw). W skrócie, trendy na 2018 rok to: Obywatel AI (Citizen AI), Rozszerzona rzeczywistość (Extended Reality), Wiarygodność danych (Data Veracity), Technologia otwarta na współpracę (Frictionless Business), Internet of Thinking.
Przyjrzyjmy się teraz ścieżce Java development by Warsaw Java User Group (było to coś pomiędzy skondensowanymi WJUG-ami odbywającymi się co czwartek a Confiturą:
-
Porty i adaptery (Dominik Przybysz). Rozumiem, że była to ta sama prezentacja co na WJUG #206 sprzed roku i konferencji 4Developers 2017. Do obejrzenia na Youtube, a slajdy na GitHubie.
-
Klienci HTTP: bohaterowie systemów rozproszonych (Adam Dubiel). Rozumiem, że to ta sama prezentacja co na Confiturze 2017. Do obejrzenia na Youtube. Byłem na niej w tamtym roku i była dosyć ciekawa. W skrócie: skupmy się na „niskopoziomowych” klientach HTTP, ich konfiguracji i sposobie działania (pule, timeouty itd.), a biblioteki przesłaniające je to tylko abstrakcja i ich wybór zależy od gustu.
-
Więcej niż Java, Spring i Hibernate razem wzięte. Trochę tajemniczy tytuł, ale wiele obiecujący. Do tego opis: „Jaki powinien być język i platforma programistyczna przyszłości?”. Spotykało się kiedyś prezentacje w tym stylu pokazujące coś innowacyjnego, co rzeczywiście było lepsze (albo chociaż było uważane za lepsze w momencie prezentacji). Miałem nadzieję na coś takiego. Inni widocznie też, bo miejsca podczas rejestracji na tą prezentację rozeszły się bardzo szybko. Wysoko postawiona poprzeczka. Czy spełnili oczekiwania?
Prezentacja zaczęła się od opowieści o projekcie, pożarach w nich, deadlinach i braku wystarczającej liczby programistów. Wstępem było zastanowienie się nad tym „czy programowanie jest łatwe?„. Z jednej strony nie, bo jest wiele technologii, które trzeba opanować (języki programowania, frameworki, architektura itd.), żeby zbudować system. Ale z drugiej strony programowanie jest też łatwe, bo nawet dzieci tworzą programy w Scratchu (jest to wizualny język programowania, przeciągamy bloczki z instrukcjami i w ten sposób obiekty na ekranie wykonują określone akcje – jest to trochę taki następca Logo Komeniusza, edukacyjnego języka programowania w którym rysowaliśmy żółwiem). Trochę naciągana odpowiedź (trudno porównywać skomplikowane systemy do edukacyjnych aplikacji), ale tok rozumowania, który kierował tym przykładem będzie dalej.Następnie przedstawiony był pomysł jak zrobić, żeby łatwiej tworzyć systemy. Chodzi o to, żeby z jednej strony oddzielić technologię od biznesu. Ale z drugiej, żeby „programować” na każdym etapie wytwarzania oprogramowania. Żeby tych samych technicznych pojęć używali wszyscy, zarówno programiści, ale też analitycy (łatwiej będzie przenieść to do kodu, wyeliminowane zostaną też nieścisłości), a także klient (który ma być włączony w proces budowy systemu). Według mnie jest to trochę sprzeczne, bo trzymanie się technicznych szczegółów na każdym etapie wytarzania oprogramowania nie jest oddzieleniem technologi od biznesu, a wręcz przeciwnie. Zaś włącznie klienta w proces budowy systemu, to przecież powszechna praktyka w Scrumie/Agile. No nic, idźmy dalej.
Kolejnym pomysłem było przejście na wyższy poziom abstrakcji, który będzie zrozumiały dla klienta. Najniżej jest asembler, potem obiekty i klasy, którymi mogą też operować analitycy i biznes, jeszcze wyżej są przypadki użycia, reguły, modele, formularze (przez prelegentów nazywane „formatkami”), transakcje, kontrolki, akcje itd.
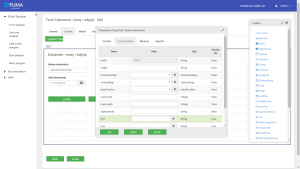
Edycja formularza na platformie PUMA. Źródło: http://puma.asseco.com, PUMA Designer Dokumentacja projektanta, s. 28
I tutaj przechodzimy do sedna. Asseco zebrało te elementy z najwyższego poziomu abstrakcji i nazwało „DNA systemu”, czyli fragmenty z których system może się składać. W wielu projektach takie kawałki się powtarzają np. logowanie, formularze itd. Różnią się tylko konfiguracją. Według prelegentów, przykładowo logowanie w Spring Security to za dużo pracy, żeby ją powtarzać. Dlatego wytworzyli te fragmenty aplikacji, aby mogły być później użyte do budowy systemu i modyfikowane. Napisali platformę deweloperską PUMA (było pytanie z publiczności czy jest to gdzieś publicznie dostępne, to została udzielona wymijająca odpowiedź, ja znalazłem tylko to – czyli nie). Dzięki niej można wyklikać (drag&drop) gotowe kawałki systemu (np. formularze) i w ten sposób niby tworzyć system. Platforma automatycznie generuje kod w Javie (te fragmenty systemu napisane są w Springu). Możliwość układania i konfiguracji na platformie możliwa jest w trzech perspektywach: w postaci diagramów (dla analityka, wysoki poziom abstrakcji), w XML, w Javie (automatycznie wygenerowany kod, który ma być dla programistów). Dzięki temu podstawowy formularz może wygenerować nawet analityk, który nie potrafi programować, ale lepiej zna domenę i wie co powinno się na nim znaleźć (i teoretycznie nie tracić czasu programistów do tak prostych rzeczy). Technicznie tworzone formularze generowane też są w Javie (prelegenci nazwali to coś à la Vaadin). Jeśli istnieje konieczność niestandardowej modyfikacji, to musi usiąść programista i zmodyfikować automatycznie wygenerowany kod.
-

- Edycja reguły na platformie PUMA. Źródło: http://puma.asseco.com, PUMA Designer Dokumentacja projektanta, s. 67
-
- Scratch – wizualny język programowania wykorzystywany do nauki programowania dla dzieci. Przykładowy projekt Pong: https://scratch.mit.edu/projects/10128515/#editor
Co o tym sądzę? Po pierwsze tytuł jest delikatnie mówiąc naciągany. Przesadzili z marketingiem. Ja się zawiodłem. Nie było przestawione żadne nowe rozwiązanie, a jedyne zastosowanie tego co już od dawna istnieje. Tytuł i opis sugerował, że to nie będzie Java i Spring, a system oczywiście jest napisany w Javie i Springu.
Przejdźmy do samego ich pomysłu. Idee może i były dobre. Ułatwić programowanie (wiadomo, brakuje ludzi, więc im będzie łatwiej, tym łatwiej kogoś znaleźć – być może Asseco mocno odczuwa problem z brakiem developerów i chciało jakoś go rozwiązać). Włączyć jak największą liczbę osób w sprawy techniczne (teraz dąży się do tego, żeby już dzieci znały podstawy programowania, także więc i dorośli z branży IT powinni kojarzyć chociaż podstawy jak działają systemy). Wyeliminować pisanie kolejny raz tych samych fragmentów w różnych systemach. Ale pomysły na ich rozwiązanie nie wyglądają na to, żeby się sprawdziły. Wizualne języki programowania początkowo wydają się dobrym rozwiązaniem, ale zazwyczaj takimi nie są. Mogą sprawdzić się w bardzo wąskich zastosowaniach np. w celach edukacyjnych jak Scratch, w określonym zakresie (LabVIEW, Matlab, Luna; o tym ostatnim tutaj wideo, można podsumować tę kwestię cytatem z tego filmu, że jeśli nie jest to konkretne zastosowanie, w którym akurat pasuje to visual program languages are bullshit). Automatyczne generowanie kodu zazwyczaj źle się kończy (na marginesie, może być jest wyjątek: generowanie kodu przez sztuczną inteligencję, ale wtedy nie jest on do czytania dla ludzi, a jeśli zachodzą zmiany to ponowne generowanie). Mogą zachwalać, ale wynikowy kod to i tak będzie nieczytelne spaghetti. Trudno będzie znaleźć chętnych programistów do tego, żeby modyfikować powstały kod. A modyfikacje będą zawsze, projektanci platformy przecież nie przewidzą wszystkiego, nigdy nie powstaje system gdzie nie są potrzebne customy (świadczy o tym to, że platforma została zaprezentowana na ścieżce WJUG-owej, czyli tam gdzie jest najwięcej programistów Javy – po co? Wydaje się, że właśnie po to, żeby ktoś pisał te customy). Pomysł miał rozwiązać problem z brakiem programistów, a może okazać się, że odniesie odwrotny skutek do zamierzonego, bo nikt z programistów nie będzie chciał przy tym pracować. Więksi od Asseco próbowali z automatycznym generowaniem kodu i tworzeniem systemów przez drag&drop i widzimy co z tego wyszło. Oracle ze swoim Oracle Designerem, którego już mało kto zna. Rozwiązanie Microsoftu z drag&drop kontrolek w Visual Studio (WinForms, WPF), jeszcze jakoś się trzyma, ale dlatego, że to tylko obsługa gotowych kontrolek na formularzu, a nie generowanie całej logiki aplikacji. Systemy powstałe w taki sposób będą trudne do utrzymania. Oczywiście cały czas dąży się do tego, aby wyeliminować powtarzalne czynności. Ale obecnie idzie się raczej we frameworki. Często wykorzystywane fragmenty w systemach zamyka się w bibliotekach. Zapewnia się to, aby ich użycie było coraz wygodniejsze i szybsze. Dzięki temu takie uniwersalne rozwiązanie mogą być z łatwością utrzymywane i używane tylko jako zależności. Przytoczony przykład z logowaniem i Spring Security – obecnie nie jest to aż tak czasochłonne, że nie można by tego użyć (zwłaszcza ze Spring Bootem, który zawiera dużo domyślnej konfiguracji). Przy okazji – od pisanie frontendu w Javie też się odchodzi (przytoczony Vaadin przez prelegentów, a także GWT, Wicket itp. kilka lat temu były u szczytu popularności). Według mnie, ta platforma może sprawdzić się jedynie do prototypowania i szybkiego wygenerowania systemu w celu prezentacji klientowi koncepcji. Utrzymanie i rozwój tak powstałego systemu rzeczywistego w rzeczywiści byłby zapewne problematyczny. Chyba że tworzone systemy są bardzo do siebie podobne i wtórne. Czekam na informację o zastosowaniu tego rozwiązania w praktyce. Jeśli by im się rzeczywiście udało, przejęliby dużą część rynku IT i to bez zatrudniania dużej liczby programistów. Nie widzę na to jednak dużej szansy.
Podsumowując: na prezentacji się zawiodłem, bo oczekiwałem czegoś innego, ale wartościowe było spojrzenie na problem z innej strony niż obecny trend. Pomysły być może nietrafione (albo nie jest to jeszcze ich czas), ale doceniam próbę innowacji i innego podejścia.
-
- Wykrywanie i usuwanie błędów w systemach rozproszonych (Kamil Szymański). Rozumiem, że to ta sama prezentacja co na WJUG-u #220 pod tytułem Nailing down bugs in distributed systems (tytuł po angielsku, ale prezentacja po polsku). Do obejrzenia na Youtube.
- Pragmatyczne podejście do pisania i utrzymywania testów (Marek Dominiak). Prezentacja z WJUG-a #188 sprzed półtora roku. Wideo na Youtube.
- Keep it clean: hexagonal architecture in practice (Jakub Nabrdalik). Ta sama prezentacja co na Confiturze 2017 (nagranie na Youtube) i na 4Developers 2017 (nagranie na Youtube). Tytuł po angielsku, ale prezentacja po polsku. Wcześniej jej nie słuchałem, ale zachęcony przez kolegę z firmy poszedłem. Nie zawiodłem się. To prezentacja z tych, które otwiera oczy i zmienia myślenie. Niejako zaraża swoim pomysłem (który jest prosty, ale logiczny; powoduje myśli „czemu wcześniej tak nie robiłem?”). W skrócie, główne myśli, które były przekazane:
- Przestać nadużywać słowa
publicw klasach. Domyślnym poziomem dostępu dla klas powinien być dostęp… domyślny (czyli inaczej pakietowy tzn. bez żadnego wpisanego modyfikatora dostępu). - Podział struktury aplikacji folder by feature zamiast folder by type. Standardowo w tutorialach są foldery ze względu na techniczne aspekty np.
model,controller,dao. Zamiast tego lepiej robić foldery ze względu na funkcjonalność. Ze swojego doświadczenia widzę, że jest to już od jakiegoś czasu dobra praktyka. W tym poście opisałem dwa typy struktur projektu w AngularJS: Routing w AngularJS i struktura aplikacji (ten drugi sposób jest własnie by feature). W najnowszym Angularze również takie podejście jest zalecane (Style Guide – Overall structural guidelines – Folders-by-feature structure). Jeśli chodzi o świat Javy, to przykładem może być to (choć jeszcze są mieszane feature z technicznymi folderami): Alfresco/records-management. - Podsumowując dwa poprzednie: jeśli folder będzie miał w sobie tylko klasy powiązane z daną funkcjonalnością, to wystarczy, że klasą publiczną będzie tylko ta, która wystawia API dla reszty klas (nie chodzi o API sieciowe np. REST, a po prostu klasy/metody publiczne, które mogą być używane przez innych). Dzięki temu analizując dany pakiet, wystarczy, że skupimy się na klasie publicznej – to jest punkt wejścia do niej. W innym wypadku musimy mieć w głowie wszystkie klasy z całego pakietu, bo wszystko może komunikować się na zewnątrz pakietu.
- Pierwsze słowo o testach: jeśli zastosujemy powyższe podejście wystarczy, że będziemy testować klasy publiczne. Dużo mniej do testowania. Zaś klasy o dostępie pakietowym będziemy mogli dowolnie refaktoryzować bez przepisywania testów.
- Drugie słowo o testach: testy jednostkowe powinny uruchamiać się szybko. W przeciwnym wypadku nikomu nie będzie się chciało ich uruchamiać, więc będą mało przydatne (o TDD nie wspominając). Aby to zrobić należy nie wchodzić na IO (np. nie zapisywać do bazy danych, a zamiast tego testować na danych w pamięci np. w
HashMap).
- Przestać nadużywać słowa
- Supermoce wzorca delegacji – na przykładzie implementacji w Kotlinie (Marcin Moskala). Prezentacja z rosyjskiego konferencji DevFest Siberia 2017 pod tytułem Superpowers of Kotlin delegation. Nagranie na Youtube, slajdy na Slides oraz artykuł na blogu Kotlin Academy. Prezentacja po polsku (w przeciwieństwie do tej oryginalnej na Youtube). Prelegent jest współautorem książki Android Development with Kotlin (ostatnio modne stało się programowanie w Kotlinie na Androida, głównie za sprawą Googla, które to zaczęło promować). Opisywał głównie przedostatni rozdział z książki o delegatach, który napisał. Jest też autorem Kotlin Academy.


Wybrane prezentacje z kolejnego dnia:
- Ansible – od zera do bohatera w 45 minut! (Jakub Muszyński). Ansible jest już dostępny od dłuższego czasu, ale ostatnio stał się modny. W skrócie, służy do automatyzacji wykonywania zadań na serwerach. Narzędzie dla adminów/DevOpsów. Jak masz coś zainstalować lub skonfigurować, to napisz skrypt i zrób to automatycznie. Niby można zrobić to w bashu, ale z Ansible ma to być wygodniejsze. Dodatkowo istnieje repozytorium z gotowymi skryptami Galaxy (coś jak Docker Hub dla Dockera). Wymagania? Na serwerze musi być Python. Materiały z prezentacji oraz sama prezentacja udostępnione zostały na Githubie sirkubax/szkolenie3. Co ważne, Ansible jest już wykorzystywany na produkcji np. w bankach. Tutaj przykładowy tutorial z Ansible z polecanego Chmurowiska. Alternatywą dla Ansible jest Terraform (pomijając inne rozwiązania, które tracą na popularności np. Chef, Puppet itd).
- Twój telefon się uczy – wprowadzenie do Tensorflow na Androidzie (Bartosz Kraszewski). Machine Learning do uczenia wymaga dużej mocy obliczeniowej (aby przyspieszyć ten proces używane są karty graficzne). Oczywiście dzisiejsze smartfony dysponują stosunkowo dużą mocą obliczeniową (i np. aplikację YOLO do rozpoznawania obrazów można uruchomić na Andriodzie, tak samo jak inne aplikacje napisane z wykorzystaniem TensorFlow). Oczywiście prędkość uczenia będzie wolniejsza niż na dedykowanym GPU w PC. Ale czy uczenie modeli rzeczywiście jest potrzebne na smartfonach? Wystarczy wziąć gotowy, wytrenowany model, wczytać go i z niego skorzystać. Prelegent trochę narzekał, że obecnie tak traktowani są programiści urządzeń mobilnych, ale chyba wszyscy powinni się do tego przyzwyczajać, że w standardowych zastosowaniach wystarczające będzie korzystanie z gotowych modeli. W ten sposób można stosunkowo szybko i łatwo, a przy tym bez wymagania dużej mocy obliczeniowej zrobić coś przydatnego i skorzystać w praktyce z tej popularności Machine Learningu.
- Going deeper: Transfer Learning (Szymon Urbański i Dominik Lewy z Lingaro). Techniczna prezentacja o Machine Learningu. Omówionych kilka algorytmów.
Przedstawiona idea skąd wziął się Machine Learning w rozpoznawaniu obrazów. Ja jeszcze ze studiów z przedmiotu Cyfrowe Przetwarzanie Obrazów pamiętam algorytmy oparte konwolucji (nakładanie „masek” na obraz, dające np. wygładzenie, wyostrzenie krawędzi lub wykrywanie krawędzi). Właśnie zaczynając od tych operacji np. filtr Sobela, mnożenia macierzy itd. powstały takie rozwiązania jak te rozwiązujące rozpoznawanie obrazów (ImageNet) za pomocą Deep Learningu np. GoogleNet, ResNet. Jak patrzy się na rozwiązania Deep Learningowe, to widzi się efekty zaskakująco duże w stosunku do użytych algorytmów. Tak samo jak z najprostszym wykrywaniem krawędzi: przejście kilku pętli z odpowiednią maską (przemnożeniem pikseli przez określone wartości) powoduje coś zaskakującego – wykrycie krawędzi.
Drugą ideą było omówienie Transfer Learningu. W skrócie: zamiast robić wszystko od początku, to wziąć już nauczony model i douczyć go, aby zastosować go w naszym przypadku. Przykładem było wzięcie modelu, który był wytrenowany do ogólnego rozpoznawania obrazów (YOLO). Prelegenci chcieli uzyskać rozwiązanie, które będzie rozpoznawało twarze konkretnych polityków (oczywiście YOLO takich szczegółowych klas nie rozpoznaje). Zrobienie wszystkiego od początku pewnie byłoby bardzo pracochłonne i efekty mogłyby nie być zadowalające. Wytrenowanie YOLO zajęło autorom dużo czasu. Prelegenci wzięli jednak ten model i dotrenowali go podając oznaczone zdjęcia twarz. W efekcie uzyskali dobre wyniki stosunkowo małym nakładem pracy. W ogóle w świecie Machine Learningu zalecane jest używanie gotowych algorytmów i przerabianie ich na swoje potrzeby. Wymyślenie czegoś od nowa co działa, może być bardzo trudne i jest to przeznaczone bardziej jako praca naukowa, a nie praktyczne zastosowanie. W podejściu Transfer Learningu bierzemy nie tylko algorytm, ale też wstępnie wytrenowany model. Oszczędność czasu i mocy obliczeniowej oraz potrzeba mniejszego zbioru danych treningowych.
Na koniec było też ogłoszenie o konkursie. Należy zastosować metodę Style Transfer (tzn. np. styl z jakiegoś obrazu przenieść na inną grafikę, to co robi Deep Dream Generator) do grafiki na github.com/Lingaro-DataScience/WDI-2018 (plansza z gry Mario). Oceniana będzie grywalność (tzn. np. widoczność przeszkód na planszy). Oczywiście rozwiązanie musi zawierać kod z użytym algorytmem. Czas do końca kwietnia 2018.
- Machine Learning – wprowadzenie (Adrianna Napiórkowska i Jacek Dziwisz). Wystąpienie to było w sekcji oznaczonej „warsztaty”. Może dla niektórych było to zaskoczenie, ale na WDI zazwyczaj warsztaty to po prostu wykład, tylko w mniejszej sali (zazwyczaj nie ma warunków np. wystarczającej liczby komputerów, żeby przeprowadzić prawdziwe warsztaty, a jeśli uczestnicy wezmą swój sprzęt, to nie ma np. internetu – z powodów opisywanych wyżej w Organizacja).
Prelegentami byli członkowie koła naukowego Business Analytics z SGH. W bardzo przystępny sposób został wyjaśniony problem przeuczenia (ang. overfitting) w uczeniu maszynowym (zbyt dokładnie dopasowanie do danych zamiast generalizacji). Przedstawione zostały podstawy jak np. podział algorytmów w uczeniu maszynowym (uczenie z nadzorem: klasyfikacja, regresja, bez nadzoru: grupowanie, ze wzmocnieniem), podział danych na zbiór treningowy i testowy (ciekawa koncepcja wydzielenia zbioru walidacyjnego ze zbioru treningowego – myślę, że to może być przydatne wszędzie tam, gdzie mamy ograniczone dane np. w konkursach lub tam gdzie dostaje gotowe zbiory), ocena jakości modelu (porównanie ilości błędów – pole pod krzywą ROC). Omówione zostały i pokazane przykłady algorytmów takich jak:perceptron (podstawowy element budowy sieci neuronowych), regresja, drzewa decyzyjne, las losowy, k-najbliższych sąsiadów (branie wyniku takiego w zależności od tego jakich próbek jest najwięcej, liczba sąsiadów jako parametr – algorytm przydatny gdy dochodzą nowe dane do tych już oszacowanych).
Przykłady były napisane w języku Python z wykorzystaniem biblioteki scikit-learn. Do prezentacji został użyty również Jupyter Notebook. Czyli standardowy zestaw w podstawach Machine Learningu. Prezentacja i przykłady zostały udostępnione na github.com/Adrianna-Na/Workshops/tree/master/WDI2018.
Na koniec było zachęcenie do uczestniczenia w spotkaniach SKN Business Analytics. O ile dobrze zrozumiałem, mogą w nich uczestniczyć nie tylko studenci. Organizowane są otwarte warsztaty (co widać w wydarzeniach w zalinkowanym fanpage na Facebooku), ale podobno też w czwartki odbywają się regularne spotkania. Z tego co usłyszałem tworzone są np. zespoły do brania udziału w konkursach lub organizacja danych do badań, a na pewno wzajemne motywowanie do rozwijania się – co właśnie koła naukowe powinny robić.
Podsumowanie
WDI w tym roku nie zawiodło. Oczywiście zmienia się, ale warto było przyjechać. Przez lata uczestniczyłem w wydarzeniu w różnych rolach, jako słuchacz, partner wydarzenia, prowadzący warsztaty, a teraz również jako wystawca. Duża liczba prezentacji, w których każdy znalazł coś dla siebie. Merytorycznie różny poziom prezentacji, ale zazwyczaj zadowalający. Oczywiście nie była to specjalistyczna konferencja (jak np. Confitura o samej Javie), ale bardziej przekrój całego świata IT. Jest to idealne miejsce, żeby poznać podstawy czegoś nowego, zobaczyć jakie są trendy.
Mam nadzieję, do zobaczenia za rok!