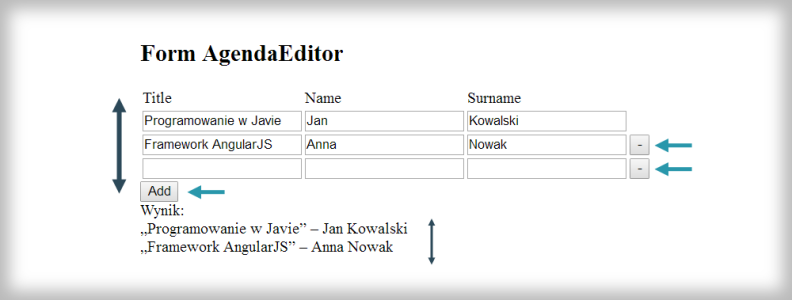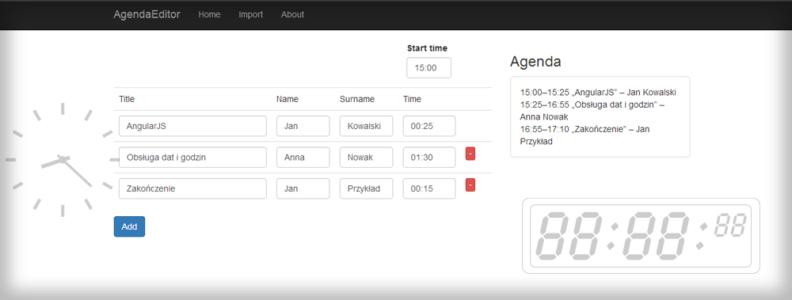
W naszej aplikacji możemy wpisywać tematy oraz imię i nazwisko prelegenta. Jednak tak naprawdę nic więcej się nie dzieje poza przepisaniem tych danych i dodaniem odpowiednich cudzysłowów i myślników. Dodajmy obliczanie godzin występów!
Chcemy do godziny rozpoczęcia wystąpienia np. 16:50 dodać jego czas trwania np. 15 minut, zapisane w formacie 00:15. Powinniśmy otrzymać godzinę zakończenia danego wystąpienia tj. 17:15. Dzięki takiemu formatowi, będziemy mogli wpisywać wystąpienia trwające dłużej niż godzinę np. półtorej godziny będzie zapisane 01:30.
W JavaScript niestety nie ma gotowej funkcji pozwalającej na sprasowanie godziny w takim formacie, ani ich dodawanie. Niemożliwe jest też dodanie własnego formatu (jak to można zrobić np. w Javie za pomocą DateTimeFormatter).
Własna funkcja dodająca godziny
Napiszmy więc własną funkcję. Chcemy przyjąć dwa parametry addTime(start, time):
- start np.
"16:50", - czas do dodania np.
"00:15".
Wynikiem wywołania funkcji addTime("16:50", "00:15") powinien być tekst: "17:05".
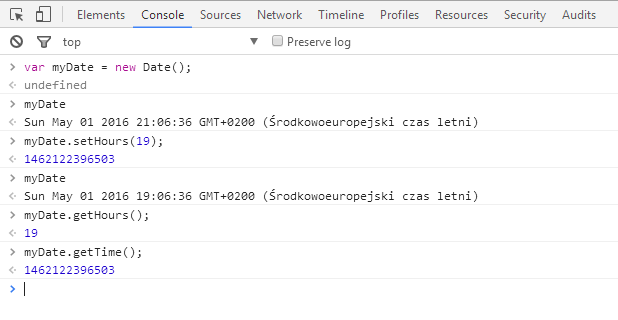
Jak zaimplementować tę funkcję? Stwórzmy nowy obiekt new Date() i przypiszmy go do jakiejś zmiennej np. o nazwie now. Ustawmy godziny i minuty z pierwszego parametru za pomocą setHours i setMinutes. Następnie pobierzmy liczbę godzin i minut z drugiego parametru i dodajmy je do naszego obiektu (osobno godziny, osobno minuty).
Przykładowo jeśli liczbą minut z pierwszego parametru będzie 50, a będziemy chcieli dodać 25, to sumą będzie 75. Co się stanie jak ustawimy to jako minuty?
|
1 2 3 4 5 |
var myDate = new Date(); myDate.setMinutes(50); myDate.getMinutes(); // 50 myDate.setMinutes(75); myDate.getMinutes(); // 15 |
Tu JavaScript zachowa się ładnie i dostaniemy dokładnie to co chcieliśmy (licznik w godzinie się „przekręci”, wskoczy następna godzina i dostaniemy prawidłową liczbę minut; jest to niejakie dzielenie modulo 60).
Jak pobrać godziny i minuty z formatu HH:mm?
Jak już wspomniałem, nie ma w JavaScript możliwości dodania własnych formaterów. Po prostu pobierzmy odpowiednie liczby z ciągu tekstowego np. za pomocą metody split.
Metoda split(separator) działa w ten sposób, że zwraca tablicę z fragmentami tekstu podzielonymi za pomocą separatora. U nas separatorem będzie dwukropek „:”.
|
1 2 |
"16:50".split(":")[0]; // 16 "16:50".split(":")[1]; // 50 |
O to nam chodziło.
Kod funkcji będzie wyglądał tak:
|
1 2 3 4 5 6 7 8 |
function addTime(start, time) { var now = new Date(); now.setHours(start.split(":")[0]); now.setMinutes(start.split(":")[1]); now.setHours(now.getHours()+parseInt(time.split(":")[0])); now.setMinutes(now.getMinutes()+parseInt(time.split(":")[1])); return now.getHours() + ":" + now.getMinutes(); }; |
Niby działa:
|
1 |
addTime("16:50", "00:25"); // dobry wynik: "17:15"<br> |
Ale w przypadku innych danych brakuje zer wiodących:
|
1 |
addTime("16:50", "00:15"); // brak zer wiodących: "17:5" |
Zera wiodące
Zauważmy, że jeśli pobierzemy godzinę, minuty lub sekundy, które są poniżej 10, to otrzymamy liczbę bez zer wiodących:
|
1 2 3 |
var myDate = new Date(); myDate.setMinutes(05); myDate.getMinutes(); |
Wynik:
|
1 |
5 |
Nie znalazłem eleganckiego rozwiązania. Trzeba po prostu zrobić if-a, który będzie to sprawdzał i doklejał „0” w odpowiednim miejscu:
|
1 2 3 4 5 |
if(myDate.getMinutes() < 10) { "0" + myDate.getMinutes(); } else { myDate.getMinutes() } |
Krócej można to zapisać:
|
1 |
(myDate.getMinutes()<10?'0':'') + myDate.getMinutes(); |
Wynikiem będzie tekst:
|
1 |
"05" |
Nasza poprawna funkcja będzie teraz wyglądać tak:
|
1 2 3 4 5 6 7 8 9 10 |
function addTime(start, time) { var now = new Date(); now.setHours(start.split(":")[0]); now.setMinutes(start.split(":")[1]); now.setHours(now.getHours()+parseInt(time.split(":")[0])); now.setMinutes(now.getMinutes()+parseInt(time.split(":")[1])); var hours = (now.getHours()<10?'0':'') + now.getHours(); var minutes = (now.getMinutes()<10?'0':'') + now.getMinutes(); return hours + ":" + minutes; }; |
Jak widzimy, teraz wszystko działa poprawnie:
|
1 2 |
addTime("16:50", "00:25"); // wynik: "17:15" addTime("16:50", "00:15"); // wynik: "17:05" |
Wykorzystanie funkcji w AgendaEditor
Mamy gotową funkcję obliczającą godziny. Dodajmy ją do projektu.
Zmiany w HTML
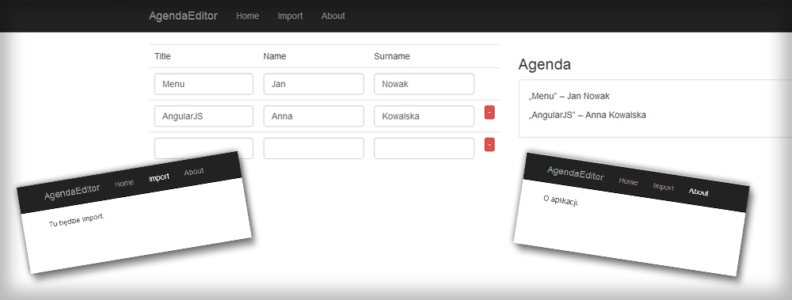
Naszym widokiem z agendą obecnie jest plik home.html. Przede wszystkim musimy dodać tam pola gdzie będziemy mogli wpisać dane. Dodanie kolumny z miejscem na czas wystąpienia („time”):
|
1 2 3 4 5 |
<td class="col-sm-5">Title</td> <td class="col-sm-2">Name</td> <td class="col-sm-2">Surname</td> <td class="col-sm-2">Time</td> <td class="col-sm-1"></td> |
Jak widzimy, system gridowy możemy stosować również do kolumn tabel, tak jak do całej strony.
Jako nowy wiersz wstawiamy dodatkowe pole analogiczne do innych:
|
1 2 3 4 5 6 7 |
<tr ng-repeat="item in list" ng-click="$last && addItem()"> <td><input class="form-control" type="text" ng-model="item.title"></td> <td><input class="form-control" type="text" ng-model="item.name"></td> <td><input class="form-control" type="text" ng-model="item.surname"></td> <td><input class="form-control" type="text" ng-model="item.time"></td> ... </tr> |
Zostało nam do dodania pole, w które będziemy wpisywać godzinę startu całego wydarzenia. Dodajmy je nad tabelą:
|
1 2 3 4 |
<div class="form-group col-sm-2 col-sm-offset-9"> <label>Start time</label> <input type="text" class="form-control" ng-model="startTime"> </div> |
Skorzystaliśmy z klasy form-group, w elemencie nią oznaczoną możemy umieścić napis label. Ustawiamy mu szerokość taką samą jak dla kolumny wyżej „Time” tzn. col-sm-2. Dodajmy również offset, który umieści pole nad kolumną tabeli „Time”. Po lewej stronie są kolumny „Title” (5), „Name” (2), „Surname” (2), co razem daje 5+2+2=9. Dlatego offset jest równy: col-sm-offset-9. Do tego nasze pole (2) i jeszcze puste miejsce, pod którym jest przycisk do usuwania (1), razem daje 12 bootstrapowych kolumn.
Zmiany w JavaScript
Przejdźmy teraz do naszego Angularowego kontrolera home.js.
Dodajmy naszą funkcję. W kodzie poniżej widzimy, że musimy ją wstawić dokładnie w kontrolerze. Nie będziemy jej przypisywać do $scope, bo nie ma takiej potrzeby (będzie wykorzystywana tylko lokalnie w kontrolerze):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
angular.module('agendaEditor') .config(function($routeProvider) { $routeProvider // ... }) .controller('homeController', function($scope) { $scope.list = []; $scope.list.push({title: "", name: "", surname: "", time: ""}); $scope.myResult = function () { //... }; $scope.addItem = function(){ // ... }; function addTime(start, time) { var now = new Date(); now.setHours(start.split(":")[0]); now.setMinutes(start.split(":")[1]); now.setHours(now.getHours()+parseInt(time.split(":")[0])); now.setMinutes(now.getMinutes()+parseInt(time.split(":")[1])); var hours = (now.getHours()<10?'0':'') + now.getHours(); var minutes = (now.getMinutes()<10?'0':'') + now.getMinutes(); return hours + ":" + minutes; }; }); |
W naszej liście $scope.list na początku umieszczamy jeden element za pomocą push. Pamiętajmy aby dodać tam nowe pole time: "", tak jak w kodzie wyżej.
Zajmijmy się teraz funkcją $scope.myResult, w której powinny wystąpić wywołania funkcji addTime, aby obliczyć godziny wystąpień.
Poprzednia wersja wyglądała tak:
|
1 2 3 4 5 6 7 8 9 10 |
$scope.myResult = function () { var result = []; for (var i = 0; i < $scope.list.length; i++) { var concat = "„" + $scope.list[i].title + "” – " + $scope.list[i].name + " " + $scope.list[i].surname; if($scope.list[i].title !== ""){ result.push(concat); } } return result; }; |
Dodajmy sobie zmienną lastTime przechowującą godzinę zakończenia poprzedniego wystąpienia. Będzie to automatycznie początek kolejnego wystąpienia. Na początku oczywiście musimy ustawić ją jako czas startowy całego wydarzenia:
|
1 |
var lastTime = $scope.startTime; |
W pętli będziemy obliczać koniec wystąpienia za pomocą naszej funkcji addTime:
|
1 2 3 4 5 6 |
for (var i = 0; i < $scope.list.length; i++) { var endTime = addTime(lastTime, $scope.list[i].time); var concat = lastTime + "–" + endTime + " „" + $scope.list[i].title + "” – " + $scope.list[i].name + " " + $scope.list[i].surname; result.push(concat); lastTime = endTime; } |
Oczywiście obliczone godziny musimy dopisywać do wykonu końcowego.
Oprócz tego dodajmy kilka warunków:
- Nie wykonuj pętli (czyli nie rób niczego z naszą listą), jeśli nie została wpisana godzina wystąpienia:
1if($scope.startTime !== "") - Nie przetwarzaj danego wiersza jeśli nie został wpisany tytuł lub jeśli nie został wpisany czas wystąpienia (czasem zdarza się pusty string a czasem
undefined).
1if($scope.list[i].title !== "" && $scope.list[i].time !== "" && $scope.list[i].time !== undefined)
Cały kod funkcji myResult będzie teraz wyglądał tak:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$scope.myResult = function () { var result = []; if($scope.startTime !== "") { var lastTime = $scope.startTime; for (var i = 0; i < $scope.list.length; i++) { if($scope.list[i].title !== "" && $scope.list[i].time !== "" && $scope.list[i].time !== undefined)){ var endTime = addTime(lastTime, $scope.list[i].time); var concat = lastTime + "–" + endTime + " „" + $scope.list[i].title + "” – " + $scope.list[i].name + " " + $scope.list[i].surname; result.push(concat); lastTime = endTime; } } } return result; }; |
Podgląd działającej aplikacji
W zakładce „Code” oczywiście można podejrzeć kod całej aplikacji. Klikając tutaj, otworzymy ją w nowej karcie.